Many, if not most, programmers leave word wrap off by default when editing code. This is because line-breaks in code can have programmatic implications. Python, for instance, uses line-breaks to indicate the end of a statement. With word wrap enabled, coders may have a difficult time distinguishing between new lines created automatically by word wrap and new lines created intentionally by a carriage return.
That’s all well and fine when you’re working with actual code, but it doesn’t work so well with documentation meant to be written in plain English (or some other traditional language). On one hand, s single long horizontal line of text isn’t very readable — newspapers invented columns for a reason — and horizontal scrolling is a pain. On the other hand, manually inserting line-breaks into text isn’t much better. Adding or removing just one word at the beginning can require deleting and re-typing all of the newlines in a paragraph. And because documentation often lives in the same file as code (i.e. as comments), most text editors apply the same word-wrapping scheme to both code and documentation.
Some text editors are smart about this and offer ways to automatically re-flow long blocks of text, but it doesn’t seem to be a universal feature in code editors. To help, I’ve put together a simple webpage that uses Javascript to convert long flowing word-wrapped paragraphs to a fixed width text. By default, it uses the industry standard width of 80 characters, but you can change that. You can also use the tool to automatically prepend each line with a characters (e.g. to insert a “#” character to conform to Python’s commenting requirements).
It also doubles as a way to convert fixed width multi-line text back to — e.g. the angle bracket quoted paragraphs in e-mails — back to a traditional word-wrapped single line of text.
You can use the tool here, or check out the source code on Github.
Most folks have probably seen some blog post or story warning them that Facebook has exposed their private messages from 2010 and before on their public timeline, which Facebook denies of course. And Facebook is (probably) right — what you’re really seeing are old wall posts that you thought were private. That’s not much solace to some Facebook users though, who — based on the message content — insist that the messages *must* have been private.
Here’s what I think really happened.
Facebook used to have a wall-to-wall feature, which showed the wall posts between you and your friend in a back-and-forth conversation format. It looked sort of like this. Or this. Because this layout looks very similar to how messages work in Facebook, people treated wall-to-wall the same way they treat private messaging. But as the name suggests, wall-to-wall posts actually go on your (very public) wall. The wall-to-wall feature was removed in late 2010. Coincidentally, people are only reporting private messages on their timeline for 2010 and earlier.
That’s not to say there hasn’t be a privacy snafu. There absolutely is. Regardless of whether they’re wall posts or PMs, old embarrassing messages on your Timeline are still embarrassing. And if that bothers you, you should hide them.
But the cause of this privacy breach isn’t some Facebook engineer inadvertently flipping the privacy bit in the FB database. It’s really a UI / design problem, or more specifically, a divergence between Facebook’s model of users behave and the user’s mental model of how Facebook behaves. Two divergences really.
The first is the aforementioned wall-to-wall issue. From Facebook’s perspective, two users were posting on each other’s public walls. But from the user’s standpoint, based on the visual cues presented to them, they were engaging in a private conversation.
The second is Timeine itself. Timeline exposes old, possibly-private and sensitive information. Again, this is because of a divergence between mental models. For Facebook, the question of whether something is public is a binary decision. When the server receives a request for some particular information, it either provides it or it doesn’t.
But for many Facebook users, public really means accessible. And accessibility isn’t quite so binary. Prior to Timeline, sifting through old messages was time-consuming and difficult (it still is in a way). So by the time an old wall post was buried several months in the past, it may still have been public (as Facebook understood it), but it was relatively inaccessible. Timeline changed the accessibility of old information, and combined with the earlier wall-to-wall issue, we ended up with a huge chunk of Facebook users thinking their private messages were exposed (and in a way, they were).
Some final takeaways / questions:
Don’t trust your memory. When it comes to technology, what matters is what the technology thinks is true, not what you remember as true. As the Wall-to-Wall issue shows, poor UI design can affect how people perceive things are happening on the backend. In this case, if you still think there’s a PM on your timeline, the easiest way to verify this is to cross-reference it against your email archives (if you have your email archived that far back and you had e-mail notifications turned on). Until recently, Facebook would send a separate e-mail for wall posts and private messages. If it’s a private message, the e-mail will say so. And you should notify Facebook, because that’s a huge $#@&-up.
Privacy is often a design problem. Same with security. Or really anything else whether the error exists between keyboard and chair.
How do you resolve old UI mistakes? Facebook was almost certainly aware that many wall posts were intended to be private, despite being marked public. But because of the mis-marking, there’s no easy way to identify what user intent actually was for many of these messages. So what’s the proper response? This actually reminds me of the 2000 election in which many Gore voters likely inadvertently voted for Buchanan. But at least some of those Buchanan voters actually intended to vote for Buchanan, and there’s no easy way to tell who intended what, short of a re-vote. So what’s the fair thing to do here?
How do you roll out new paradigms with old data? Start-ups are all about rapid growth and change. Lots of iterations. The occasional pivot. The problem is this can look a lot like a bait-and-switch. Users may provide a company private information based on implicit assumptions on how that data is being used. And indeed, the company may share those assumptions, at least initially. But start-ups often to change course. Sometimes those changes may seem slight from the start-up’s perspective but strongly conflict with the user’s assumptions about how the data is handled. In such case, what’s the best way for a start-up to handle that?
Just finished a 33 days / 9332 mile road trip trough 28 states and one province.
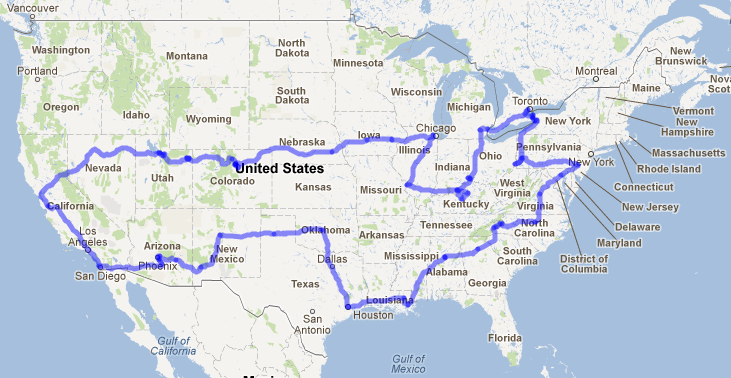
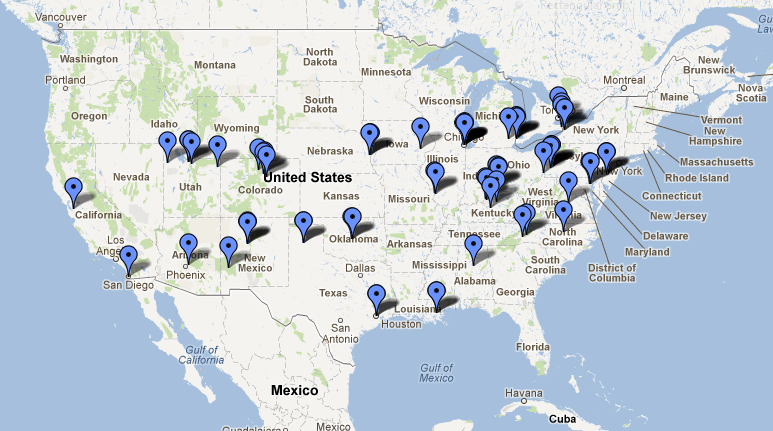
Route and places visited on Google Maps.
Jotting down some rough thoughts on how new tech + more lawyers affects different parts of the legal market (apologies for typos):
Big Law
**Large firms catering to large corporations, or more accurately, well-known partners catering to large corporations. Presumably, number of large corporations isn’t increasing relative to number of lawyers. Also, number of big law firms and well-known partners increase slowly because of the big law feedback loop — i.e. the only way you get to be a big firm is if you win big cases, and the only way you get big cases is by already being a big firm.
So for big law, your underlying demand (corporations) remains untouched. And your underlying supply (firms) is the same. But that doesn’t mean no change. More law students = more competitive to get a big law job. Effect of new technology — productivity per lawyer increases, and since caseload is fixed, lawyers per firm drops. You could argue that firms might hire more lawyers and ask them to do less work for less salary. But that’s unlikely — there are fixed costs per lawyer — HR, office space, etc. So firms are likely to hire fewer lawyers, but require higher productivity (ugh). And you’ll see the price tag for big law drop, although this will be the result of fewer hours billed rather than a lower hourly billing rate (assuming we don’t nix the hourly system altogether).
Solo Practitioner
Difference story for people hanging out a shingle. Supply is more closely linked to number of lawyers rather than number of firms, so legal costs should go down more dramatically. But this also depends on the nature of the legal services offered.
If you’re offering services with minimal court or client interaction — e.g. helping a small business owner incorporate, filing basic wills, drafting run-of-the-mill employment contract, etc. — technology works to your advantage. These things scale well. You have to charge a lower price per client, but you can also cater to more clients, so it’s a net wash. And if you’re sufficiently entrepreneurial, you can also seek out “underserved” clients, thereby expanding the market. For example, I normally wouldn’t pay a lawyer to review the purchase agreement for a new car. But suppose I could use my smartphone to snap a photo of the agreement and e-mail it to a lawyer. Normally, it’d take the lawyer an hour to review the entire contract, but by using pattern-recognition software to highlight unusual terms, she can send back her analysis of the contract in 15 minutes at a total cost of $100. I don’t know about you, but if it’s a $10K+ car, that seems reasonable.
On the other hand, if you’re dealing with legal services that require more interaction with people — e.g. child custody fights, criminal defense, landlord/tenant, etc. — then life is rough. New tech may help you do legal research or fill out forms faster, but it doesn’t do much to speed up interviewing a client or appearing in court. And you still have more competition, so you can’t charge as much as you used to.
Ethics
Some of this stuff poses an ethics problem as well. In order to compensate for the lower income-per-client, a lot of lawyers are going to take on more cases. To some extent, it’s great that more clients are able to get legal services at lower cost. But a lot of these lawyers are also going to take on more cases than they handle. And when it comes to stuff like child custody or criminal defense, that’ll get ugly. If it’s one thing that law school should teach, it’s time and case management.
A few years ago, a friend asked me that if I could insist upon one trait in my child, what would it be? I picked ambition.
My fifth year reunion is wrapping up now, and one thing I realize is that I used to be ambitious. Ridiculously so. Like take-over-the-world ambitious. Maybe I’m mellowing out and settling for a quiet life. A career. Maybe I’ll meet someone and settle down and have two-and-a-half-children and live in suburbia and drive a minivan. I’ll be a respectable lawyer working for big companies at a white shoe firm, and if I’m lucky, maybe I’ll be a cartoonist too — that sort of life. Choice C instead of “all of the above”. A world where I don’t call and hope others call me. Maybe.
We’ll see what happens to me. I hope there are explosions involved. But if not, I still hope my children end up ambitious. And I especially hope for that if my child ends up being a girl.
One of my favorite professors in law school has a daughter, and I remember him telling my class that he was worried that social stereotypes would pressure her to reject math and science. So he went out of his way to make find and make mathematical puzzles for her to solve, in the hopes that she might love math and science as much as he did.
Hopefully, that won’t backfire. My parents tried to make me a math-science wiz. And largely because of that, I dropped out of Computer Science and majored in “Government”. Oops. But I understand and respect the motive.
If I ever have a daughter, I probably won’t insist she be a math / science wiz. But I will insist that she be ambitious. Like take-over-the-world ambitious. Like Sheryl Sandberg meets Hillary Clinton ambitious. And she’ll probably hate me for it. But if I had a choice, that’s the daughter I’d choose. I hope she chooses that too.
P.S. If you actually are my daughter and you end up reading this through the magic of the Internet, no pressure. Also, listen to your mom. I don’t know she is, but she’s right.
{kind=link}